Alicia-M 模仿学习系统介绍
LeRobot 提供了一个覆盖机器人学习完整生命周期的统一框架,功能涵盖 数据采集、模型训练、算法验证与部署 四个环节,帮助研究者和开发者高效地实现从感知到控制的闭环开发。以下是基于LeRobot的灵动-云擎遥操套件的模仿学习示例。
1. 安装与环境准备
1.1 创建 Python 环境
conda create -n lerobot python=3.11 -y
conda activate lerobot
1.2 安装依赖
git clone https://github.com/Synria-Robotics/lerobot.git -b v6.1.1-beta
cd lerobot
pip install -e .
验证安装:
lerobot-record --help
lerobot-train --help
如果没有出现not command相关信息则说明lerobot安装成功
1.3 验证Alicia SDK
python -c "import alicia_d_sdk, alicia_m_sdk; print('Alicia SDKs OK')"
如果你看到:
Alicia SDKs OK
说明两个 SDK 都已经装好。
如果这里报错
单独安装sdk,安装完成之后再运行步骤4的SDK验证
pip install alicia-m-sdk
pip install alicia_d_sdk
以上环境只需要安装一次即可
2 单遥操套件物块抓取
采用的设备/物品:
- Alicia M操作臂;
- 灵动Alicia-DL示教臂
- 两个D405 RealSense 相机;
- 2.5 cm x 2.5 cm 正方体;
- 收纳盒;
2.1 激活环境
cd lerobot
conda activate lerobot
2.2 端口检测
将两个摄像头连接至电脑,尽量连接电脑两个USB口,一个扩展坞不要连接两个摄像,可能供电不够导致读取不到图像;(如果使用扩展坞连接两个,则需要额外供电)
2.2.1 摄像头检测
python examples/camera/camera_detection.py
运行之后会打印出摄像头端口,分别是video5和video12
Found 2 usable camera stream(s).
Press 'q' in the video window to cycle to the next camera.
Displaying Camera 1/2: TSTC USB20 WEB CAMERA on /dev/video5
Closing feed for TSTC USB20 WEB CAMERA.
Displaying Camera 2/2: Intel(R) RealSense(TM) Depth Ca (usb-0000 on /dev/video12
Closing feed for Intel(R) RealSense(TM) Depth Ca (usb-0000.
All camera streams have been shown. Exiting.
然后运行下面这个查看摄像头详细信息
lerobot-find-cameras opencv

找到对应的摄像头例如video5 这边显示Width和Height均为 640 * 480,为后续使用
2.2.2 检测机械臂串口
首先通过操作臂USB连接电脑,然后执行
ls /dev/ttyACM*
会提示ttyACM0,然后连接示教臂,再执行一次上面命令,可以看到ttyACM0 ttyACM1,因此操作臂对应ttyACM0,示教臂对应ttyACM1
注意:设备编号顺序不固定,请以实际检测结果为准,不要默认操作臂 Alicia-M 一定是 /dev/ttyACM0。
2.3 数据采集
2.3.1 采集测试
推荐先录制 1 回合做自检
下面这条命令适合先做一轮设备连通性检查:
需要注意的参数有--robot.port --robot.cameras --teleop.port这几个需要对应好,这些参数就是上面检测的,对应上才能顺利采集
lerobot-record \
--robot.type=alicia_m_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{front: {type: opencv, index_or_path: /dev/video5, width: 640, height: 480, fps: 30}, wrist: {type: opencv, index_or_path: /dev/video12, width: 640, height: 480, fps: 30}}" \
--robot.id=alicia_m \
--teleop.type=alicia_d_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.gripper_type=50mm \
--teleop.directly_controls_robot=false \
--teleop.target_follower_type=alicia_m \
--teleop.id=alicia_d \
--dataset.repo_id=user/pick_and_place_v0 \
--dataset.root=data/pick_and_place_v0 \
--dataset.num_episodes=1 \
--dataset.single_task="pick and place" \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=15 \
--display_data=true \
--dataset.push_to_hub=false
确认动作方向、相机和串口都正常后,再把 --dataset.num_episodes 改大开始正式采集。由于data/pick_and_place_v0已经存在,可以先删除,或者是在运行修改下面的--dataset.root=data/pick_and_place_v0 为 --dataset.root=data/pick_and_place_v1
2.3.2 正式采集
lerobot-record \
--robot.type=alicia_m_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{front: {type: opencv, index_or_path: /dev/video5, width: 640, height: 480, fps: 30}, wrist: {type: opencv, index_or_path: /dev/video12, width: 640, height: 480, fps: 30}}" \
--robot.id=alicia_m \
--teleop.type=alicia_d_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.gripper_type=50mm \
--teleop.directly_controls_robot=false \
--teleop.target_follower_type=alicia_m \
--teleop.id=alicia_d \
--dataset.repo_id=user/pick_and_place_v0 \
--dataset.root=data/pick_and_place_v0 \
--dataset.num_episodes=30 \
--dataset.single_task="pick and place" \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=15 \
--display_data=true \
--dataset.push_to_hub=false
运行这个采集代码,核心作用是采集30条数据( --dataset.num_episodes=30)这个数据集主要是抓取和放置物块(--dataset.single_task="pick and place"),每条数据集最长时间为30s(--dataset.episode_time_s=30),采集完成一条数据之后,会有15s的环境重置时间,重新摆放物块(--dataset.reset_time_s=15),会显示窗口查看采集的图像和机械臂信息(--display_data=true)默认不上传到hub保存(--dataset.push_to_hub=false),只保存本地。采集结束后数据会保存到本项目的data/pick_and_place_v0 (--dataset.root=data/pick_and_place_v0)
下图是Rerun可视化页面
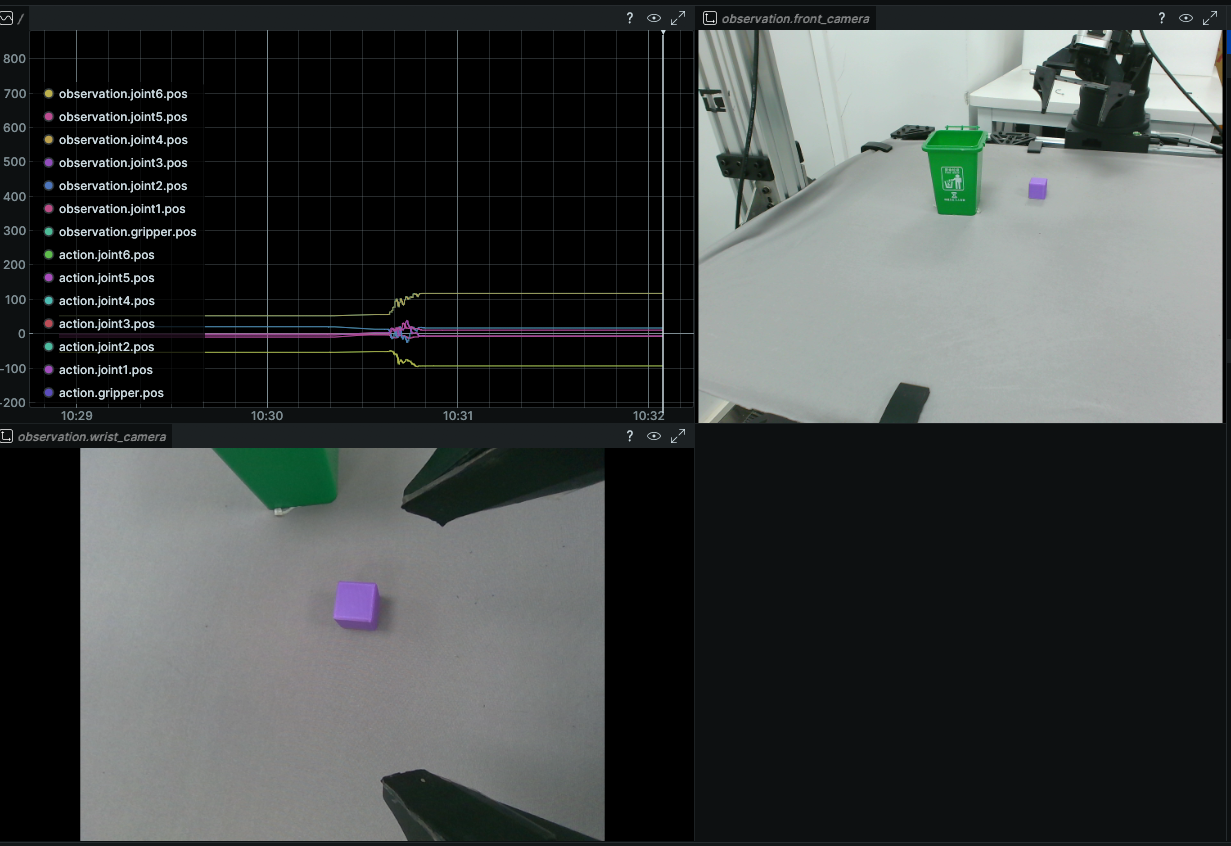
录制的过程中
-
按下方向键
<-可以重新录制当前回合 -
按下方向键
->结束当前回合录制(如果我提前完成任务,可以按下这个提前结束) -
按下 ESC 停止录制
2.3.3 继续采集
要在已有数据集上继续追加 episode,可以使用:
lerobot-record \
... \
--resume=true
恢复录制时要参数和原始数据集一致,在后面添加--resume=true
如果不一致,LeRobot 会报 Dataset metadata compatibility check failed。
2.3.3 参数详细说明
Robot 参数
| 参数名 | 本例填写 | 作用 |
|---|---|---|
--robot.type | alicia_m_follower | 指定被控设备是 Alicia-M follower。 |
--robot.port | /dev/ttyACM0 | Alicia-M 的串口设备。实际使用时请以端口检测结果为准。 |
--robot.cameras | front 和 wrist 两路相机 | 配置录制相机。front、wrist 是相机名字;type: opencv 表示使用 OpenCV 相机;index_or_path 是视频设备路径;width、height、fps 分别表示分辨率和帧率。录制、训练、推理阶段建议保持相机名字一致。 |
--robot.id | alicia_m | 机器人实例 ID,用于区分设备,也会影响校准文件和日志标识。 |
Teleop 参数
| 参数名 | 本例填写 | 作用 |
|---|---|---|
--teleop.type | alicia_d_leader | 指定示教设备类型是 Alicia-D leader。 |
--teleop.port | /dev/ttyACM1 | Alicia-D leader 的串口设备。实际使用时请以端口检测结果为准。 |
--teleop.gripper_type | 50mm | Alicia-D 的夹爪规格,需要和真实硬件一致。 |
--teleop.directly_controls_robot | false | 表示 Alicia-D 不直接通过硬件线控制 follower,而是由计算机读取动作后再转发给 Alicia-M。 |
--teleop.target_follower_type | alicia_m | 表示 Alicia-D 读到的关节值要按 Alicia-M 的关节约定映射后输出。 |
--teleop.id | alicia_d | 示教设备实例 ID,用于区分设备和日志标识。 |
Dataset 参数
| 参数名 | 本例填写 | 作用 |
|---|---|---|
--dataset.repo_id | user/pick_and_place_v0 | 数据集逻辑标识,格式通常是 用户名/数据集名。即使只保存在本地,这个字段也建议按这个格式填写。 |
--dataset.root | data/pick_and_place_v0 | 本地数据集保存目录。 |
--dataset.num_episodes | 30 | 要录制的 episode 数量,也就是要采集多少条示教数据。 |
--dataset.single_task | "pick and place" | 任务文本描述,会写入数据集。这个参数必须提供。 |
--dataset.episode_time_s | 30 | 每个 episode 最长录制时长,单位是秒。 |
--dataset.reset_time_s | 15 | 每个 episode 结束后,留给人工复位场景的时间,单位是秒。 |
--dataset.push_to_hub | false | 录制结束后不自动上传到 Hugging Face Hub,只保存在本地。 |
其他参数
| 参数名 | 本例填写 | 作用 |
|---|---|---|
--display_data | true | 在 Rerun 中显示当前观测和动作,便于调试。它不会改变数据集内容,只影响可视化。 |
2.4 策略训练
这一部分的目标是:把刚才录制好的示教数据,训练成一个可以自动完成抓取和放置的策略模型。
2.4.1 训练前检查
- 先确认数据集已经录制完成,例如本例的数据集目录是
data/pick_and_place_v0 - 训练命令里的
--dataset.repo_id和--dataset.root要与录制时保持一致 - 建议至少录制
20-30条数据,想要效果更稳建议50条以上 - 如果训练机有 NVIDIA GPU,就使用
--policy.device=cuda;如果没有 GPU,也可以改成cpu,只是速度会明显变慢 - 第一次训练建议先不要同时修改太多参数,先按文档跑通一遍
2.4.2 训练 ACT(推荐先从这里开始)
lerobot-train \
--dataset.repo_id=user/pick_and_place_v0 \
--dataset.root=data/pick_and_place_v0 \
--dataset.video_backend=pyav \
--policy.type=act \
--policy.device=cuda \
--policy.push_to_hub=false \
--output_dir=outputs/train/act_pick_and_place \
--job_name=pick_and_place \
--batch_size=16 \
--steps=50000 \
--save_freq=5000 \
--log_freq=100 \
--eval_freq=0
上面这条命令的含义可以简单理解为:
--policy.type=act:训练一个ACT模型--dataset.repo_id和--dataset.root:指定要读取哪个本地数据集--output_dir:训练结果保存位置--batch_size=16:每次训练读取 16 批数据;如果显存不够,可以改成8、4甚至2--steps=50000:总训练步数;第一次先用这个数值就可以--eval_freq=0:关闭模拟环境评估,只做离线训练
训练过程中,终端会持续打印日志和 loss。loss 上下波动是正常现象,只要没有持续报错或出现 NaN,通常可以继续训练。
训练完成后,重点看这个目录:
outputs/train/act_pick_and_place/checkpoints/last/pretrained_model
如果这个目录里能看到下面几个文件,就说明模型已经成功保存:
config.jsonmodel.safetensorstrain_config.json
2.4.3 ACT 继续训练 / 断点续训
如果训练中断了,或者想把 50000 步继续训练到 100000 步,可以执行:
lerobot-train \
--config_path=outputs/train/act_pick_and_place/checkpoints/last/pretrained_model \
--resume=true \
--steps=100000 \
--save_freq=5000 \
--log_freq=100
这里需要注意:
--config_path要指向pretrained_model目录,或者直接指向里面的train_config.json- 不要把路径写成
.../checkpoints/050000这一层,否则很容易找不到配置文件 - 续训时通常不需要再把数据集、模型类型等参数全部重复写一遍
2.4.4 ACT 推理
推理的意思就是:让训练好的模型接管 Alicia-M,自动执行任务。
第一次推理前,建议先做这 4 件事:
- 清空机械臂周围容易碰撞的杂物
- 保持相机位置、物块摆放方式、起始姿态尽量接近录制数据时的状态
- 先只跑
1个回合,确认动作方向和速度正常 - 随时准备断电或急停,不要一开始就长时间连续运行
推荐先用下面这条命令做一次最小验证:
lerobot-record \
--policy.path=outputs/train/act_pick_and_place/checkpoints/last/pretrained_model \
--policy.device=cuda \
--robot.type=alicia_m_follower \
--robot.port=/dev/ttyACM0 \
--robot.cameras="{front: {type: opencv, index_or_path: /dev/video5, width: 640, height: 480, fps: 30}, wrist: {type: opencv, index_or_path: /dev/video12, width: 640, height: 480, fps: 30}}" \
--robot.id=alicia_m \
--teleop.type=alicia_d_leader \
--teleop.port=/dev/ttyACM1 \
--teleop.gripper_type=50mm \
--teleop.directly_controls_robot=false \
--teleop.target_follower_type=alicia_m \
--teleop.id=alicia_d \
--dataset.repo_id=temp/eval_act_pick_and_place \
--dataset.root=data/eval_act_pick_and_place \
--dataset.num_episodes=1 \
--dataset.single_task="pick and place" \
--dataset.episode_time_s=30 \
--dataset.reset_time_s=15 \
--display_data=true \
--dataset.push_to_hub=false
这条命令和录制数据集的命令很像,但推理阶段最关键的新增参数是:
--policy.path=.../pretrained_model:表示这次不是人工示教,而是加载训练好的 ACT 模型来控制机器人
下面把推理命令按用途拆开讲,这样后面你在换模型、换相机或做安全调参时,会更容易知道该改哪一项。
模型加载参数
| 参数名 | 本例填写 | 作用和修改建议 |
|---|---|---|
--policy.path | outputs/train/act_pick_and_place/checkpoints/last/pretrained_model | 指向要加载的策略目录。这里必须是 pretrained_model 这一层,目录中至少要有 config.json、model.safetensors、train_config.json。如果想测试某个固定 checkpoint,可以把 last 改成具体步数目录,例如 050000/pretrained_model。 |
--policy.device | cuda | 指定模型在哪个设备上推理。推荐优先用 cuda,这样动作延迟更低;如果当前机器没有可用的 NVIDIA GPU,可以改成 cpu,但控制响应会明显变慢。 |
机器人与观测参数
| 参数名 | 本例填写 | 作用和修改建议 |
|---|---|---|
--robot.type | alicia_m_follower | 指定被 ACT 控制的是 Alicia-M follower。这个参数要和真实硬件类型一致。 |
--robot.port | /dev/ttyACM0 | Alicia-M 的串口。换 USB 口后这个值可能会变,推理前最好重新确认一次。 |
--robot.cameras | front 和 wrist 两路相机 | 这是推理效果最敏感的参数之一。front、wrist 这些名字不是随便写的,它们对应模型训练时使用的观测键名。推理阶段最好保持与录制时相同的相机名字、分辨率、帧率和安装位置,否则模型看到的输入分布会变化,成功率通常会下降。 |
--robot.id | alicia_m | 机器人实例 ID,主要用于区分设备和关联日志/配置。通常沿用录制数据时的填写即可。 |
--robot.max_relative_target | 本例未写,建议首次推理时追加 8 | 这是一个常用的安全限幅参数,用来限制每个控制周期允许的相对目标变化幅度。值越小,动作越慢、越保守;值越大,动作更快,但更容易出现突跳。第一次上线建议从较小值开始试。 |
如果第一次推理时动作幅度偏大、看起来不够安全,可以先补充:
--robot.max_relative_target=8
Teleop 相关参数
| 参数名 | 本例填写 | 作用和修改建议 |
|---|---|---|
--teleop.type | alicia_d_leader | 指定示教臂设备类型。示例里仍按 Alicia-D leader 这套配置初始化。 |
--teleop.port | /dev/ttyACM1 | Alicia-D leader 的串口。和 --robot.port 一样,换口后要重新确认。 |
--teleop.gripper_type | 50mm | 示教臂夹爪规格,要和真实硬件一致。 |
--teleop.directly_controls_robot | false | 表示 Alicia-D 不通过同步线直接驱动 Alicia-M,而是由电脑统一读入并转发控制逻辑。若你的接线方式不同,这个参数也要跟着改。 |
--teleop.target_follower_type | alicia_m | 指定 leader 的关节数据要按 Alicia-M 的关节约定做映射。这个值如果写错,动作方向或关节对应关系可能会异常。 |
--teleop.id | alicia_d | 示教设备实例 ID,用于日志和设备区分。通常不需要频繁修改。 |
评估数据与回合控制参数
| 参数名 | 本例填写 | 作用和修改建议 |
|---|---|---|
--dataset.repo_id | temp/eval_act_pick_and_place | 评估数据的逻辑标识。这里保存的是模型自动执行时产生的评估数据,不是训练权重本身。 |
--dataset.root | data/eval_act_pick_and_place | 本地评估数据目录。推理结束后,你可以到这里回看每个 episode 的执行结果。 |
--dataset.num_episodes | 1 | 本次自动运行多少个回合。第一次调试建议先设成 1,确认动作正常后再增加。 |
--dataset.single_task | "pick and place" | 当前任务描述。建议和训练数据的任务语义保持一致,便于后续回看、筛选和对比评估结果。 |
--dataset.episode_time_s | 30 | 单个回合最长持续时间。太短可能任务还没做完就强制结束;太长则在模型异常时会增加风险。 |
--dataset.reset_time_s | 15 | 一个回合结束后给人工复位场景的时间。物块需要重新摆放、机械臂需要回到安全起点时,就调大这个值。 |
--dataset.push_to_hub | false | 推理结束后不上传到 Hub,只保存本地。首次验证建议保持 false。 |
--display_data | true | 打开可视化窗口,方便观察相机画面、机器人状态和动作输出。第一次推理建议开启,排查问题更直观。 |
第一次推理时建议怎么调
一个比较稳妥的调试顺序是:
- 保持
--dataset.num_episodes=1、--display_data=true,只做一回合短时间验证。 - 如果动作太猛,就先降低
--robot.max_relative_target;如果动作明显过慢,再逐步调大。 - 确认动作方向、抓取时机和复位流程都正常后,再增加
--dataset.num_episodes做连续评估。
如果模型能正常加载、机械臂开始根据相机画面做动作,并且评估数据目录成功生成,就说明 ACT 推理流程已经跑通。